欢迎大家来到第四章,富集数据资源。
我会为大家介绍什么叫做富集资源以及富集哪些资源。

- 概述
首先,富集词典词槽。这是指需要收集到任务完成的关键词和关键要素。类似电影院、所有的App名称、航班信息,都叫词典词槽。这些需要我们尽可能多的收集到。
其次,富集对话样本,对话样本是真实的业务场景中的对话集合。
最后,富集问答对,问答对是真实业务场景中的问答集合。
如上是需要要富集的资源。
接下来为大家简单介绍富集的三种方法:
第一,从指定业务场景中提取数据;
第二,从对话的日志中抽取相关数据;
第三,去网上收集。如电影名称、电影院名称等,这些有官方的数据库,可以直接下载,其他没有数据库的,可以去垂直的社区论坛上爬取。

- 富集词典词槽
什么叫做富集词槽词典?简单来说,就是获取更多实体编辑数据。例如,当你要做一个打开手机App功能的机器人,如果你收集了所有常用的App名称,识别的准确率会更高。富集词槽词典有一个通用的标准,每一个词槽关键词,至少要标出3到5个相关的关键词。
换句话解释:
词典+规则+预置词槽=你的词槽
UNIT里已经预置了很多的词槽,帮助各位省去了官方数据库下载和垂直网站爬取的工作量。

富集词槽词典的原则是:
-
尽量复用系统的预置词槽
-
使用自定义词典,规则主要是补充用的,因为我们自定义的词槽可能未必有百度预置的词槽更全。
有以下3个技巧:
-
自定义词典、规则的优先级高于系统内置。
-
自定义词槽之间的优先级相等。如果一个词属于多个词槽,相应的,需要识别出多个词槽候选。
-
规则的形式是正则表达式,注意控制通配符的范围,善用捕捉功能加以限制。
考虑到很多读者并不是程序员,也不知道什么叫做正则表达式。所以在这一章,简单介绍下正则表达式。

- 正则表达式介绍
正则表达式描述了一种字符串匹配的模式,用来检查一个串是否含有某种子串,将匹配的子串替换,或从某个串中抽取符合某个条件的字串等。
上述描述是一个很官方的定义。
简单的来说,正则表达式用一种模版去匹配一句话里边是否有符合这个模版的东西,并把它抽取出来。正则表达式非常复杂,有非常多的通配符,这里只介绍了两个:
-
问号: 问号匹配字符串中的零或一个字符
-
星号:星号匹配零个或多个字符。
如图所示,一个正则表达式将要匹配图中所示的文件。\w代表任意一个字母或数字或下划线,问号匹配零或一个字符,所以可以看到它都可以匹配。*匹配零个或多个字符,所以我们看到这些也都是可以匹配的。
更多的正则表达式信息,各位可以到官网了解更多。
如上,读者可以知道富集词槽词典涉及到正则表达式的时候,该如何去使用。
- 富集对话样本 & 问答对
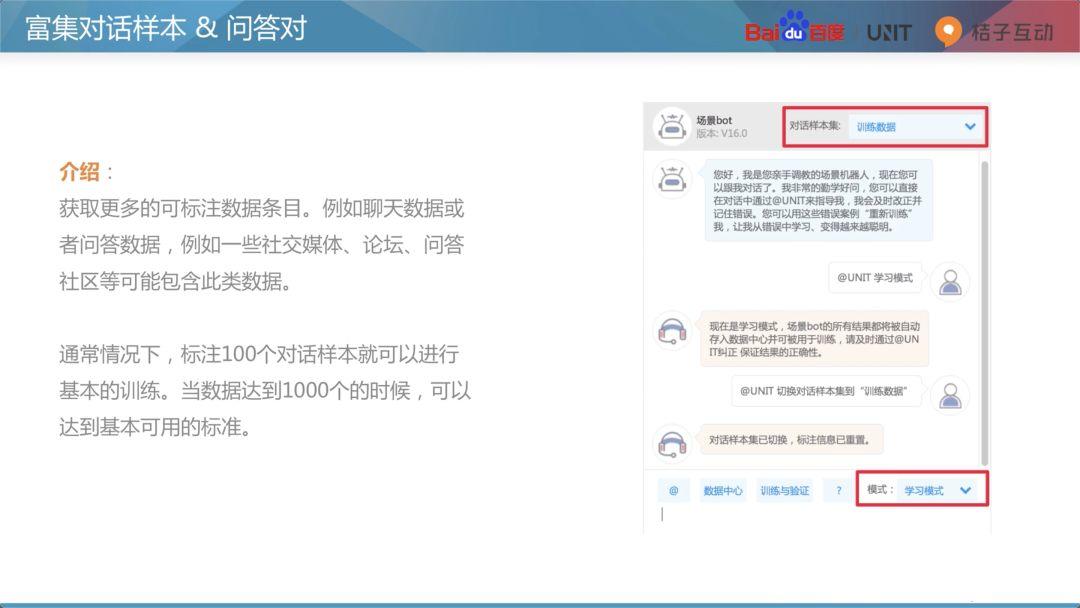
富集对话样本和问答对是为了获取更多的可标注数据的条目。比如聊天数据或问答数据。在社交媒体、论坛、问答社区等都可能包含这类数据。
富集的标准:通常情况下,标注100个对话样本,就可以进行基本训练。当数据达到1000个的时候,基本上整个系统就已经达到了可用的标准。UNIT提供了一个很好的功能——对话样本集,有学习模式和训练模式,输入对话样本,UNIT可以自行录入,并且可以在这里进行简单的标注。后面会在实操的时候给读者做详细讲解。
- 标注对话模版
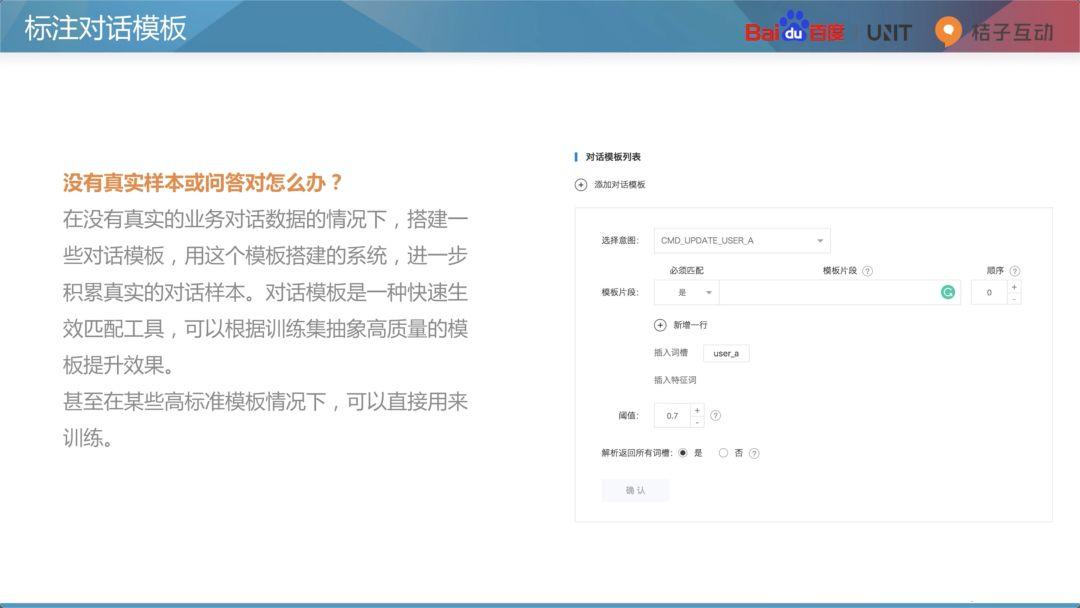
当开始搭建聊天机器人的时候,通常情况是没有真实的样本和问答对的。因为机器人还没有上线,开发者一定不知道用户如何去和Bot进行交互。这个时候是很难找100个对话对的。
要解决上述问题,标注对话模版是一个很实用的功能。先搭建一个对话模版并上线,上线后再进一步积累真实的对话样本数据,再进行数据富集,是一个很好的冷启动方法。
对话模版是一种快速生效的工具,开发者可以根据训练集抽象高质量的模版提升效果。如果模版标准比较高,有的时候也可以直接拿来做训练。上图是UNIT上对话模版列表的一个配置界面,之后在实操课程里会进一步给大家解释。
- 数据后续处理
富集数据资源还有一个很重要的步骤是数据的后续处理,这个分为三块:
第一块是数据清洗,使用正则表达式等工具,将没有用的数据区去掉,比如语气词”啊“,”哎“等,或者人名,电话号等敏感信息。
第二步是数据标注,部分数据需要后续的人工标注才能使用。包括意图分类、领域分类,槽值与实体的标注等。
第三块是数据变形,通过对特定数据的变形处理,可以兼容更多场景。比如常见的文本资料里经常会出现中文标点和英文标点混合使用的情况。可能出现“地、的、得”被混用的情况,应该尽可能的做一些合理的数据变形,使得机器能够识别更多的内容。
如上,给大家介绍了一下富集数据资源,这节课就到这里,谢谢大家!
评论